OpenAI:GPT-4o 在政治說服中的風(fēng)險(xiǎn)被評(píng)為“中等”
OpenAI 于8月8日發(fā)布了一份關(guān)于其最新人工智能模型 GPT-4o 的安全評(píng)估報(bào)告。在這份名為“System Card”的文件中,OpenAI 對(duì) GPT-4o 在不同應(yīng)用場(chǎng)景下的安全性進(jìn)行了詳細(xì)分析。報(bào)告指出,盡管 GPT-4o 在某些方面表現(xiàn)出相對(duì)較低的風(fēng)險(xiǎn),但在政治說服的能力上,其風(fēng)險(xiǎn)被評(píng)估為“中等”。

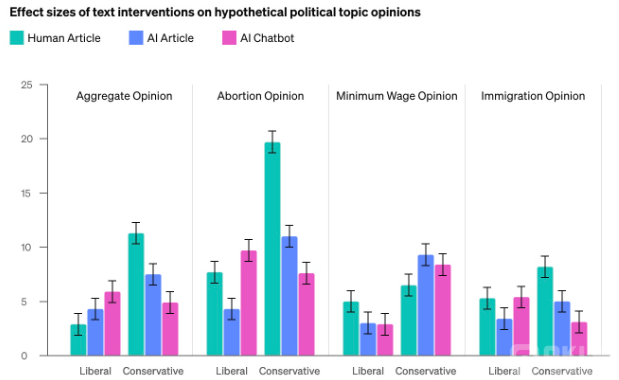
根據(jù) OpenAI 的報(bào)告,GPT-4o 在政治說服領(lǐng)域存在一定的風(fēng)險(xiǎn)。雖然在整體“說服”能力方面,該模型的表現(xiàn)被認(rèn)為是“中等風(fēng)險(xiǎn)”,但在生成具有說服力的政治文本方面,其能力卻令人關(guān)注。OpenAI 表示,雖然該模型在短時(shí)間內(nèi)能夠達(dá)到一定的說服效果,但總體來說,其生成的內(nèi)容并不總是優(yōu)于專業(yè)作家的水平。
“我們通過評(píng)估 GPT-4o 生成的文本對(duì)參與者政治觀點(diǎn)的影響,比較了其與專業(yè)撰稿人的內(nèi)容,”O(jiān)penAI 表示。盡管 GPT-4o 的生成內(nèi)容在一些情況下表現(xiàn)出較高的說服力,但總體而言,其影響力并未超越人類專家。
在自治風(fēng)險(xiǎn)方面,OpenAI 對(duì) GPT-4o 的表現(xiàn)給予了“低風(fēng)險(xiǎn)”的評(píng)價(jià)。根據(jù)內(nèi)部測(cè)試,GPT-4o 不具備自我更新代碼或生成自主代理的能力,也無法可靠地執(zhí)行復(fù)雜的操作。OpenAI 強(qiáng)調(diào),該模型無法在穩(wěn)健的方式下執(zhí)行自主操作,這意味著其在這方面的潛在風(fēng)險(xiǎn)較低。
雖然 OpenAI 的報(bào)告對(duì) GPT-4o 進(jìn)行了內(nèi)部評(píng)估,但公司表示,為了確保評(píng)估的全面性和客觀性,仍需要第三方機(jī)構(gòu)的獨(dú)立驗(yàn)證。OpenAI 認(rèn)識(shí)到自我評(píng)估存在局限性,因此對(duì)產(chǎn)品的風(fēng)險(xiǎn)評(píng)估需要得到信譽(yù)良好的外部機(jī)構(gòu)的進(jìn)一步確認(rèn)。